Mitos sobre la escalabilidad de aplicaciones web
Cómo escalar una aplicación web es el debate más cansino y poco productivo que hay en el mundo de la informática. Es cansino porque se suele discutir con argumentos muy peregrinos y confundiendo los conceptos más básicos.
No suele suceder que alguien diga: "he hecho unas pruebas de estrés y he visto que para una concurrencia de 300.000 usuarios haciendo unas 5.000 peticiones por segundo las queries a las tablas de usuarios y productos dan un 85% de fallos. ¿Qué tal si denormalizamos tal campo, añadimos este índice y cacheamos estas peticiones?" No, eso que sería algo concreto, productivo y acertado. En vez de eso, lo que se oye más a menudo son argumentos como: "no podemos desarrollar la aplicación en Ruby (o Java, o lo que sea) porque Ruby (o Java o lo que sea) es lento y no puede escalar. Utilicemos mejor X", dónde X puede ser cualquier tecnología desde PHP (extrañamente, en la imaginación popular PHP es más rápido que Java) hasta C, ensamblador o html estático. Cuanto más obsoleta esté la tecnología, mejor.
Si alguien os suelta algo así, tened claro que vuestro interlocutor no tiene idea de lo que habla y os hará falta mucha pedagogía para intentar convencerlo de lo contrario. El primer paso es concretar qué significa exactamente escalabilidad.
Definición de escalabilidad
Para que un sistema sea escalable tiene que cumplir tres condiciones:
Tiene que poder adaptarse a un incremento en el número de usuarios.
Tiene que poder adaptarse a un incremento en el tamaño de los datos que maneja.
Tiene que ser mantenible.
Cuanto más fácil sea cumplir estas tres condiciones, más escalable será el sistema.
Y ahora, llegamos al punto que más confusión crea al hablar de escalabilidad: la escalabilidad no es lo mismo que el rendimiento del sistema. El rendimiento (performance) de la aplicación se define como la velocidad a la que procesa las peticiones. Pues bien, en general se puede mejorar fácilmente el rendimiento de las aplicaciones que son escalables, pero lo contrario no es cierto: una aplicación puede rendir muy bien pero no ser escalable.
Para entender este punto concretemos con un par de ejemplos.
Primero, imaginemos el siguiente servlet:
```java public void doGet (HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
Thread.sleep(4000); //Nos echamos una siesta antes de responder
PrintWriter out = response.getWriter();
out.println("Hello, world, I'm a slow but scalable servlet");
out.close();
} ```
Esta aplicación tiene un rendimiento muy malo: tarda 4 segundos en procesar una petición en la que literalmente no hace nada. Sin embargo, es una aplicación escalable según el criterio que usamos anteriormente: la aplicación no maneja datos por lo que eso no puede ser un problema. Y el mantenimiento de 7 líneas de código no debería ser una pesadilla. Por último, la aplicación puede atender a un número indefinido de usuarios simplemente añadiendo más máquinas. Si una máquina puede atender 1.000 usuarios, al añadir una segunda máquina se prodría atender a 2.000, por lo que se dice que tiene una escalabilidad lineal. La escalabilidad lineal es la mejor que se puede conseguir en sistemas grandes.
Ahora, en cambio, imaginemos una aplicación web con un alto rendimiento en el que el tiempo de respuesta medio es de 40ms, lo cual está francamente bien. No obstante, la aplicación guarda su estado en memoria de forma que cuando aumenta el tráfico del sitio no podemos simplemente añadir otra máquina al sistema porque los cambios aplicados a un nodo no se propagarán a otro. Esta aplicación tiene muy buen rendimiento pero no es escalable según nuestra definición.
Entonces, si el rendimiento no es el factor crucial que determina la escalabilidad, ¿qué hace escalable a una aplicación web? ¿Cuales son las estrategias más sencillas para escalar una aplicación web? Por los ejemplos anteriores ya podemos intuir que la escalabilidad depende más del diseño de la aplicación que de las tecnologías usadas para implementarla.
Escalabilidad horizontal y escalabilidad vertical
La estrategia más sencilla para escalar una aplicación web es simplemente comprar hardware mejor y más caro. Si nuestro hardware actual puede servir 100 peticiones por segundo, cuando alcancemos ese límite podemos actualizar la máquina a una con más potencia y así servir más peticiones. Esto se conoce como escalabilidad vertical.
La sabiduría popular nos dice que la escalabilidad vertical tiene un límite: llegados a cierto punto, simplemente no hay máquinas más caras, por lo que no se puede seguir escalando verticalmente. Además, el precio de las máquinas suele aumentar exponencialmente con su potencia, por lo que la escalabilidad vertical suele ser una opción cara.
La ventaja de la escalabilidad vertical es su sencillez: no hay que hacer ningún cambio en la aplicación, simplemente gastarse el dinero en una máquina más grande. Y, además, la escalabilidad vertical cuenta con la ayuda de la ley de Moore: para un precio fijo, la máquina que puedes comprar será cada año más potente. Si con tus máquinas actuales puedes dar servicio a 50.000 usuarios y no planeas superar este límite hasta dentro de al menos un par de años, puedes limitarte a esperar con lo que tienes. Cuando pasen los dos años puedes comprar máquinas más potentes por el mismo precio que te costaron las que tienes ahora.
Aunque parezca una estrategia demasiado sencilla para dar resultado, lo cierto es que puede funcionar muy bien. Los chicos de 37 Signals, que siempre se distinguen por encontrar soluciones sencillas a los problemas complejos, la emplean satisfactoriamente para escalar su base de datos.
Para aplicaciones realmente muy grandes, sin embargo, la escalabilidad vertical no es una opción, por lo que los gigantes de la web como Facebook, Google o Flickr, se decantan principalmente por la escalabilidad horizontal. La escalabilidad horizontal consiste en añadir más máquinas a la aplicación, aumentando su número aunque no necesariamente su potencia.
El mejor ejemplo de este paradigma es la arquitectura de Google. La plataforma en la que corre el famoso buscador está compuesta de decenas de miles de máquinas de hardware utilitario. Entre tanto hardware barato es normal que cada día decenas de máquinas dejen de funcionar por problemas de hardware, pero eso no supone un problema grave: el sistema es capaz de redirigir automáticamente el tráfico de un nodo caído a los nodos sanos y seguir funcionando como si tal cosa. Para aumentar su capacidad, Google sólo tiene que comprar más máquinas y ponerlas a funcionar.
Viendo como funciona Google, la escalabilidad horizontal parece no tener límites, pero ¿qué características debe tener una aplicación para poder escalar horizontalmente?
Arquitectura shared nothing
Para que las aplicaciones puedan escalar horizontalmente se suele utilizar una arquitectura shared nothing. En una arquitectura shared nothing cada uno de los nodos de la aplicación son independientes, autocontenidos y autosuficientes. Como cada nodo puede trabajar por sí solo sin depender de sistemas externos, al aumentar la demanda se pueden añadir tantos nodos nuevos como sean necesarios para cubrirla. Gracias a los servicios en la nube como Amazon EC2 o el Google App Engine el coste de añadir nuevos nodos es cada vez más bajo. Simplemente se crea una imagen del disco duro del sistema con la aplicación y se programa para que arranque automáticamente. Si la afluencia de público aumenta considerablemente se pueden arrancar nuevas instancias para cubrir la demanda.
Una característica importante de la arquitectura shared nothing es que el estado de la aplicación no se guarda en los nodos individuales sino que es compartida por todo el sistema. De esta forma, si algún nodo falla no se pierde información y el sistema puede seguir funcionando. Esta es la estrategia que usa Google para tener una plataforma de proporciones titánicas.
Capa de persistencia y NoSQL
Las aplicaciones web bien diseñadas suelen tener una arquitectura casi shared nothing. Simplificando, algo parecido a esto:
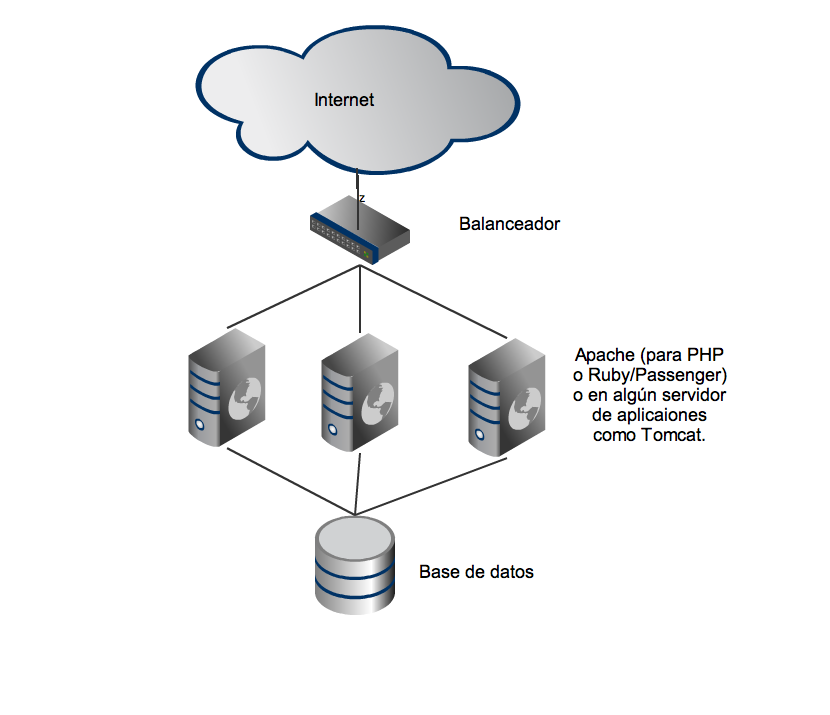
Si los nodos no guardan ningún estado propio, la capa de aplicación de esta arquitectura se puede escalar horizontalmente de forma trivial: sólo hay que añadir más apaches o servidores de aplicación. ¿Pero qué pasa con la base de datos?
La base datos es el punto compartido por todo el sistema, la única parte que se aleja de una arquitectura shared nothing y, por lo tanto, suele ser el principal punto de contención de una aplicación web y la parte más difícil de escalar. Eso no quiere decir que no existan técnicas para escalar una base de datos, las hay y muy eficientes como el sharding o la replicación. Sitios como Flickr o eBay funcionan perfectamente con sus bases de datos MySQL y si a Flickr se basta con MySQL, eso quiere decir que MySQL se puede escalar muchíiiisismo.
Otros gigantes de la Web, sin embargo, no han tenido tanta paciencia con los problemas de escalabilidad de las bases de datos tradicionales. El primero en romper el molde con un diseño innovador fue Google con su BigTable. Le han seguido otros como Amazon con su Dynamo, o Facebook con Cassandra. Todos estos proyectos se caracterizan por abandonar la tradicional base de datos basada en SQL en favor de un diseño de base de datos distribuida de alta escalabilidad.
Hasta hace unos años, sólo las empresas como Google con una capacidad de desarrollo e investigación bestiales podían permitirse el lujo de desarrollar una base de datos no relacional. Sin embargo, hoy día, hay cada vez más bases de datos no relacionales al alcance del usuario final. Entre las opciones Open Source tenemos, por ejemplo, Cassandra, MongoDB, CouchDB, Project Voldemort, Redis, etc. Estos proyectos han nacido en los últimos años y se agrupan en lo que se conoce como el movimiento NoSQL. Las bases de datos NoSQL ya se pueden usar en proyectos grandes y pequeños sin demasiada complicación y en el futuro prometen ser la respuesta a los problemas de escalabilidad de la capa de persistencia en aplicaciones web.
Para qué sirve toda esta información
Todo este rollo sobre escalabilidad puede parecer más complejo de lo que es. En realidad, creo que con tener unos conceptos básicos es suficiente, aunque si quieres aprender el tema en profundidad, te recomiendo encarecidamente que leas Building Scalable Web Sites de Cal Henderson. Cal Henderson ha sido el ingeniero encargado de escalar la plataforma de Flickr, así que ten por seguro que habla con conocimiento de causa. La mayoría de los conceptos de este artículo están sacados de ese libro. Otra fuente de información muy interesante, con multitud de ejemplos prácticos, es el sitio web High Scalability.
Recordemos también que, según nuestra definición, para que una aplicación escale debe ser mantenible y, en la inmensa mayoría de los casos lo que suele hacer a las aplicaciones inmantenibles son los malos diseños y el código mal escrito, no las avalanchas de usuarios. Un buen diseño es la mejor garantía de que tu aplicación podrá escalar bien, no el que utilices C o ensamblador para procesar las peticiones.
Sobre todo, espero que este artículo sirva para que te puedas ahorrar alguna de esas discusiones sobre escalabilidad tan poco productivas. Ten en cuenta, que siempre es mejor no optimizar antes de tiempo. Primero céntrate en hacer una aplicación que funcione y sea sencilla y elegante. Siguiendo algunas pautas sencillas como hacer que cada nodo sea autocontenido e independiente de los demás no va a haber ningún problema grave.
Una vez la aplicación esté construida y funcione bien, entonces, si quieres mejorar el rendimiento (que no la escalabilidad) haz pruebas de estrés y busca los verdaderos cuellos de botella de la aplicación. Seguramente te sorprendan. Luego, teniendo datos reales de qué hace la aplicación y qué operaciones son más costosas, entonces, puedes dedicarte a mejorar estos puntos concretos.
Como escribió Donald Knuth:
Los programadores desperdician enormes cantidades de tiempo preocupándose por la velocidad de partes de sus programas, y esos intentos de ser eficientes en realidad tienen un impacto muy negativo en el mantenimiento y la depuración del software. Deberíamos olvidarnos de las pequeñas eficiencias, digamos el 97% del tiempo: la optimización prematura es la raíz de todos los males.
Comments